
Written by Dominique Dittert, Senior Security Consultant, usd HeroLab
In the dynamic field of cybersecurity, it is often the obscure and long-forgotten vulnerabilities that pose a hidden threat to otherwise hardened systems. One such vulnerability lies in invalid character encodings that violate the UTF-8 standard. While overlong UTF-8 encodings may seem like an esoteric topic reserved for those deep in the trenches of encoding standards, the security implications can be profound and are worth considering. As this issue first surfaced over two decades ago, it has since been largely forgotten. Therefore, it is time to revisit this issue now to bring back some memories.
In this post, we will look at the basics of Unicode encoding and use that as a foundation for understanding the technical intricacies of invalid, overlong UTF-8 sequences. Armed with this knowledge, we can begin to explore the associated security risks. Along the way, we will also look at the evolution of this issue over time, from historical exploits, through the introduction of stricter standards and best practices, to modern examples of this vulnerability. We will conclude by discussing how we, as pentesters, can detect this vulnerability and what tools can help us do so.
Introduction to Unicode and UTF-8
To understand the security implications of overlong UTF-8 encodings, it is essential to first grasp the basics of Unicode and UTF-8 encoding mechanisms.
Unicode is a text encoding standard designed to support the diverse range of characters used in modern computing. Each character in Unicode is assigned a unique code point, an integer value between 0 and 1,114,111 that provides a universal reference. The standard notation is a hexadecimal number prefixed with “U+”, e.g., U+000061 for the letter “a”, which corresponds to the integer value 97 of the code point. However, two leading zeros are often omitted, resulting in the notation U+0061 for the character “a”. A contiguous group of 216 = 65,536 code points is called a plane. There are 17 planes that correspond to the numbers 00 to 10 in the first two positions of the hexadecimal notation. As of version 15.1, released on September 12, 2023, five of these planes have code points assigned, with currently 149,813 defined characters. The first plane (plane 0) is called the Basic Multilingual Plane (BMP). It contains characters from modern languages worldwide as well as symbols. Each plane is further subdivided into blocks. The BMP plane for example contains the block “Basic Latin” that is equivalent to ASCII (U+0000-U+007F) followed by Greek and Cyrillic characters. Most of the code points in the BMP plane are assigned to Chinese, Japanese and Korean characters. Plane 1 is called the Supplementary Multilingual Plane (SMP). It contains historical scripts like Archaic Greek, certain mathematical symbols, music notations and emojis. The Unicode Standard explicitly defines the three encoding forms UTF-8, UTF-16, and UTF-32.
UTF-8, which stands for Unicode Transformation Format - 8-bit, is particularly notable for its backward compatibility with ASCII, making it the most widely used encoding of the three. It is a variable-length encoding system, meaning that the representations of different characters can be of different lengths. For the commonly used characters within the ASCII range (0 to 127), the UTF-8 representation is identical to the ASCII representation, utilizing a single byte. For characters outside this range, UTF-8 employs multiple bytes (ranging from two to four) to represent each character based on its Unicode code point.
The structure of UTF-8 encoding varies depending on the range of the Unicode code point it represents:
Single-byte sequences(0xxxxxxx)are used for ASCII characters, i.e., code points up to U+007F.
- The leading bit is always
0. - The remaining 7 bits directly represent the character's code point (including leading zeros).
Two-byte sequences (110xxxxx 10xxxxxx) are used for code points in the range U+0080 to U+07FF.
- The first byte starts with the bits
110, indicating a two-byte sequence. - The next 5 bits of the first byte come from the character's code point (including leading zeros).
- The second byte starts with
10, followed by 6 bits from the character's code point.
Three-byte sequences (1110xxxx 10xxxxxx 10xxxxxx) are used for code points in the range U+0800 to U+FFFF.
- The first byte starts with
1110, indicating a three-byte sequence. - The next 4 bits of the first byte come from the character's code point (including leading zeros).
- Both the second and third bytes start with
10and are followed by 6 bits each from the character's code point.
Four-byte sequences (11110xxx 10xxxxxx 10xxxxxx 10xxxxxx) are used for code points in the range U+010000 to U+10FFFF.
- The first byte starts with
11110, indicating a four-byte sequence. - The next 3 bits of the first byte come from the character's code point (including leading zeros).
- The second, third, and fourth bytes each start with
10and are followed by 6 bits from the character's code point.
The first bits of the start byte thereby indicate the length of the whole sequence. The following bytes starting with 10 are called continuation bytes.
To illustrate the encoding process, consider the following examples of characters and their corresponding UTF-8 representations. For clarity, the bits of the binary code point are color-coded to match the byte of the UTF-8 representation to which they contribute.

Overlong UTF-8 Sequences
According to the Unicode Standard, characters should be encoded using the minimum number of bytes required to hold the significant bits of a code point. However, by padding a code point with leading zeros, it is possible to increase the number of bytes in an encoding. Using the character “a” from the table above as an example, we can create alternative encodings as follows:
- We need the binary representation of the code point. For
a, which is hex61, this is110 0001. - We can then inflate this to 11 bits by adding four leading zeros:
000 0110 0001 - Now, we must prepend the first byte with 110 for a two-byte UTF-8 sequence and the second byte with 10 for a continuation byte to create valid UTF-8 bytes. This results in
11000001 10100001or hexC1 A1.
Applying the steps above, even longer byte sequences can be created. The following table shows examples of valid and overlong encodings for two different characters. The first encoding with a length of one or two bytes is the valid encoding and the following rows show overlong variants. For better readability, the significant bits of the character are highlighted in green and orange while the padded zeros are grey and the UTF-8 specific bits are printed in bold font.

Such representations are typically referred to as overlong encodings and decoders should not accept them. In fact, the UTF-8 Encoding Specification (RFC 3629) explicitly prohibits overlong sequences:
Implementations of the decoding algorithm above MUST protect against decoding invalid sequences. For instance, a naive implementation may decode the overlong UTF-8 sequence C0 80 into the character U+0000, or the surrogate pair ED A1 8C ED BE B4 into U+233B4. Decoding invalid sequences may have security consequences or cause other problems.
Security Risks Associated with Overlong UTF-8 Encodings
After understanding how overlong UTF-8 sequences are created, we can focus on their security implications.
One significant risk is using invalid encodings for bypassing input validation and filter rules. It is no secret that input validation is a complex and nuanced process that must accommodate a multitude of special cases. Especially when using denylists, it is almost impossible to ensure that all potential encodings of a character are encompassed. Since overlong encodings are not covered by the Unicode standard, it is natural for developers to assume a standard-compliant parser when designing filter rules. However, if the parser accepts and decodes invalid overlong UTF-8 sequences after filtering, it becomes dangerous. In this case, malicious actors can exploit overlong UTF-8 sequences to perform various attacks such as path traversals, cross-site scripting (XSS), SQL injection, or command injection. These attacks often rely on the ability to encode characters in unexpected ways, allowing attackers to bypass security checks that rely on standard encoding forms. For example, an overlong UTF-8 encoded slash (/) might evade a filter designed to prevent directory traversal, thereby granting unauthorized access to sensitive files.
Another critical issue is buffer overflows, which can arise from the discrepancy between byte length and character length. When handling UTF-8 encoded input, applications must consider both the byte length and character length of the input. If an application allocates a buffer based on character length but processes input based on byte length, not only overlong UTF-8 encodings but even valid multibyte UTF-8 characters can cause a buffer overflow. However, in case of a limited character set within the ASCII range, developers might assume that byte length and character length always coincide. In this case, valid multibyte sequences will not occur, but overlong encodings can still result in buffer overflows, leading to memory corruption and potentially allowing arbitrary code execution.
Furthermore, using an invalid start byte can lead to consuming the beginning of concatenated application data. Attackers can end their input with the start byte of an UTF-8 multibyte sequence. If the parser accepts overlong UTF-8 sequences and does not check continuation bytes for validity, the first bytes of any data concatenated to this input will be assumed to be part of the last byte of the input. This can lead to various unintended behaviors, including data corruption, application crashes, and security bypasses. For instance, an invalid start byte might truncate or alter application data, such as removing closing tags in HTML, which could enable attackers to bypass security mechanisms like input sanitization or access controls.
In summary, while parsers accepting and decoding overlong UTF-8 sequences can theoretically lead to critical vulnerabilities, exploiting this issue generally requires multiple other misconfigurations or implementation errors, like filtering input prior to parsing using a denylist. In an ideal world where all other components are configured and implemented according to best practices, a parser that accepts overlong UTF-8 sequences would typically cause minimal harm, such as triggering an internal server error or a bad request for the specific instance. Nevertheless, addressing this issue should be part of comprehensive system and application hardening. Because overlooking it can occasionally lead to significant security problems, especially in environments with legacy code or custom implementations that do not adhere to modern standards.
Evolution of UTF-8 Security Issues Over Time
Having discussed the strong attack requirements to cause critical impact, one might wonder if this is still an issue today. So, let’s take a step back and revisit the first vulnerabilities associated with invalid UTF-8 encodings.
One of the earliest vulnerabilities mentioning overlong UTF-8 encoding is CVE-2000-0884. A flaw in Microsoft IIS 4.0 and 5.0 allowed attackers to read documents outside the web root and execute arbitrary commands by using the overlong encoding of the slash (/) character. Similarly, by encoding the dot (.) character using an overlong sequence, versions of Apache Tomcat prior to 6.0.18 allowed directory traversal (CVE-2008-2938). Another early example is CVE-2004-2579, which allowed to bypass access control rules in Novell iChain 2.3 by using overlong encodings of escape sequences. Furthermore, the UTF-8 parser and filter functions in older versions of PHP did not handle overlong UTF-8 sequences correctly, which led to bypassing of XSS and SQL injection protection mechanisms (e.g., CVE-2009-4142 and CVE-2010-3870) and integer overflows (CVE-2009-5016).
A lot has changed since then. Initially, the cybersecurity community began to recognize these issues through the first CVEs discussed above. This growing awareness led to the introduction of stricter standards, notably RFC 3629, which redefined the UTF-8 standard to prohibit overlong encodings. As a result, libraries and frameworks began to implement these updated standards, leading to improved input validation and sanitization practices. In addition, the widespread adoption of best practices has mostly mitigated the risk associated with overlong UTF-8 encodings in modern systems. Regular updates and better coding practices have played a significant role in this progress.
However, especially in legacy code and custom implementations where older, less secure practices may still be in use, the issue remains relevant today. In addition, faulty error handling can lead to Denial of Service (DoS) caused by invalid UTF-8 sequences. Two recent examples are CVE-2023-26302 and CVE-2024-2689. Problems with input filtering often arise when Unicode input is normalized to ASCII characters. CVE-2024-34078 describes a vulnerability using Unicode characters that normalize to chevrons (< and >) to evade sanitization.
Even today there are still prominent examples of UTF-8 parsers that do not conform to the standard. One example is Java’s ObjectInputStream class. This class deserializes primitive data and objects written using an ObjectOutputStream. It implements the interface DataInput that uses a slightly modified version of UTF-8, which uses only 1-, 2- and 3-byte representations. Still, the same logic of overlong encodings applies. The readUTF method provided by the interface decodes a given sequence as follows. If the first byte a of a group matches the pattern 110xxxxx, a two-byte sequence is assumed, and it is checked whether the second byte b starts with 10. If the check is passed, the character is converted using the code:
(char)(((a & 0x1F) << 6) | (b & 0x3F))
This will accept overlong representations. Consider the overlong encoding C1 A1 (11000001 10100001) of the character “a” from above. First, a bitwise AND between the first byte and 0x0F = 00011111 is computed to extract the significant bits of the code point (00001 in our example). The result is shifted left by 6 (resulting in 00001000000) and concatenated with the bitwise AND between byte b and 0x3F = 00111111. For the overlong encoded character “a” this results in (000)01100001, which corresponds to hex 61 or the character “a”.
A three-byte long sequence is decoded following the same logic using the code
(char)(((a & 0x0F) << 12) | ((b & 0x3F) << 6) | (c & 0x3F))
An adversary can convert some characters in the byte stream into illegal overlong representations which could allow to bypass protection mechanisms like WAFs. A similar issue that was not yet assigned a CVE was discovered in the Hessian binary web service protocol.
How to Test for Vulnerabilities Associated with Invalid Encodings
Testing for parsers that accept overlong or invalid UTF-8 sequences can reveal weaknesses in an application's input handling that might otherwise go unnoticed. Here are some strategies for effectively testing for these vulnerabilities:
If the application echoes some input back to the user, submitting input with invalid encodings and observing the output can test its handling of certain UTF-8 sequences. For example, entering a string with overlong encoded ASCII characters and seeing those characters decoded and displayed without error may indicate susceptibility to this vulnerability. An example from a pentest last November illustrates this. The tested API tokenizes credit card numbers (PANs). Besides returning the token, it also echoes back the input PAN. This allows to examine the behavior of the parser directly. In the request, the characters of the card number 4111111111111111 in the field value were replaced by the following invalid overlong UTF-8 sequences:
| Character | Overlong 2-Byte Sequence | Displayed As |
1 | C0 B1 | ˱ |
4 | C0 B6 | À´ |
POST /api/card
Host: [redacted]
Content-Type: application/json
Authorization: Bearer [redacted]
Content-Length: 46
{
"value": " ˫˱˱˱˱˱˱˱˱˱˱˱˱˱˱˱"
}
The corresponding response shows that the API accepts the overlong UTF-8 sequence, which is decoded to the correct ASCII characters, indicating a faulty parser:
HTTP/2 200 OK
Date: Fri, 24 Nov 2023 11:54:40 GMT
Content-Type: application/json
[...]
{
"token":"411111953441168R",
"pan”:"4111111111111111"
}
For fields that require specific formats, such as dates or numbers, using invalid encodings for critical characters in those formats can be telling. For example, encoding the dash in a date with an overlong sequence may indicate whether the application correctly identifies the input as invalid.
When the application retrieves data based on user input, e.g., using a name or ID, encoding part of the identifier with an invalid sequence can be helpful. Observing any changes in the behavior of the application based on the encoding can indicate a parsing issue.
If the application accepts the invalid encoded input, it is essential to check whether we can use this to bypass filters. In cases where the application concatenates data to the user input, using a multibyte start sequence could potentially disrupt the intended processing. This can help to identify weaknesses in the way the application handles parsing and concatenation operations.
Oftentimes, the application will simply throw an error when faced with an invalid encoding, which is the correct and expected response. However, identifying applications that handle such input differently can highlight potential security concerns. As an example, the following screenshot shows a test application using a vulnerable parser. While the application filters the input in the file parameter for characters used in path traversal, it makes the mistake of filtering prior to decoding. This enables attackers to use the overlong UTF-8 representation C0 AF (displayed as À¯) of the character / to read files outside of the dedicated directory:
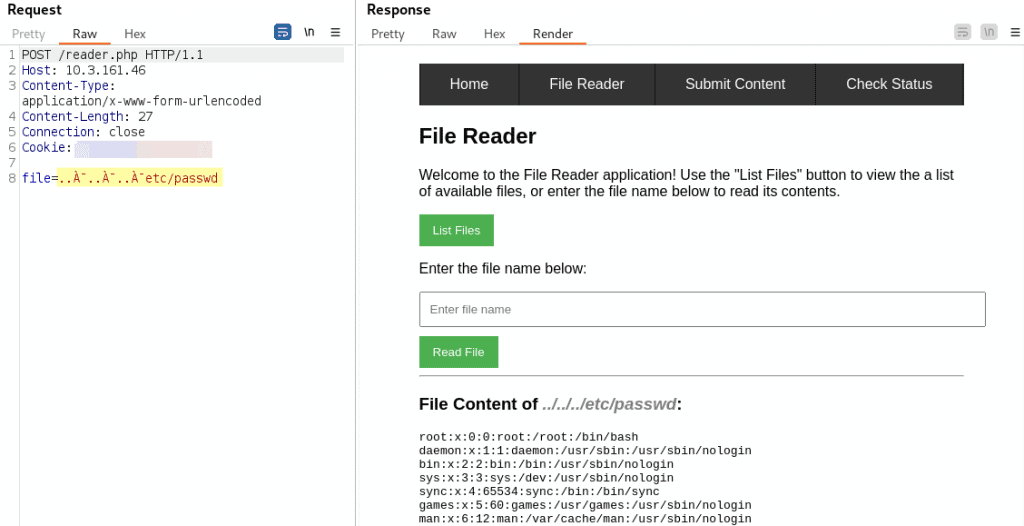
Hopefully, the previous sections have sparked your curiosity and creativity to try obscure inputs and experiment with coding anomalies. If so, the following tools can make the task easier:
Burp Suite’s Intruder includes a payload type called Illegal Unicode that replaces specified characters with various illegal encodings using a match and replace rule. The following screenshot shows the configuration of this payload set.
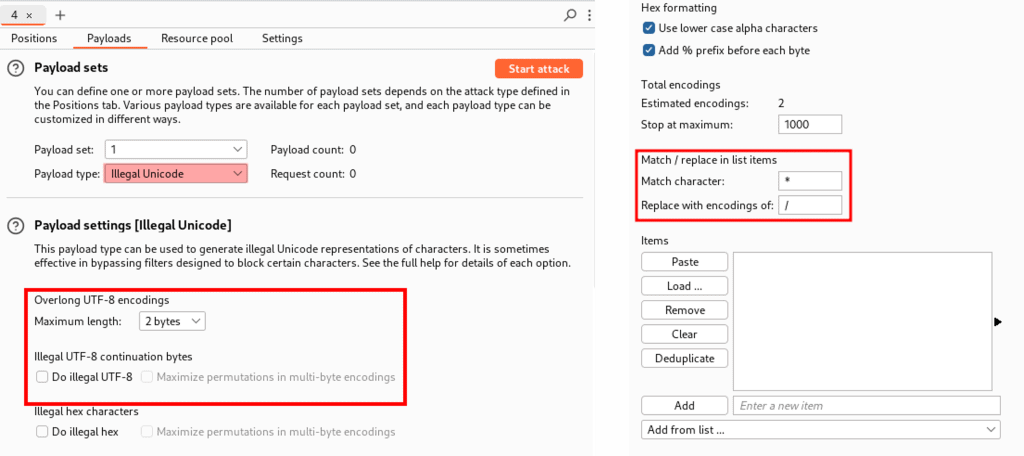
The advantage is that this payload list makes systematically testing multiple input fields for this weakness easy. However, the rigid match and replace rule restricts each test to only one invalidly encoded character.
The tool SQLmap provides a tamper script specifically for modifying payloads with overlong UTF-8 encodings. The script can be invoked with the option --tamper=overlongutf8. This script converts all non-alphanumerical characters into overlong UTF-8 sequences. In contrast, the script overlongutf8more converts all characters into their overlong representation. Other tamper scripts allow to replace apostrophes (‘) with their fullwidth variant (apostrophemask) or its illegal double Unicode counterpart (apostrophenullencode).
For manual testing, a simple Python script can help computing overlong representations of ASCII characters. The following excerpt of the script computes the overlong two-byte sequence of a character.
def compute_overlong_sequences(char): ascii_code = ord(char) # 2-byte sequence sequence = [0xc0 + (ascii_code >> 6), 0x80 + (ascii_code & 0x3f)] # [Other sequences omitted for brevity]
The table below explains the code step by step and shows an exemplary computation for the character ‘a’.
| Code | Explanation | Example |
| ord(char) | get the ASCII code | char = ‘a’: ascii_code = 97, binary 01100001 |
| First byte | ||
| 0xc0 | 11000000 (2-byte start byte) | |
| ascii_code >> 6 | extract top two bits | shifting 01100001 right by 6 bits is 00000001 |
| add the results | 11000000 + 00000001 = 11000001 = 0xc1 | |
| Second byte | ||
| 0x80 | 10000000 (continuation byte) | |
| ascii_code & 0x3f | extract lower six bits | 01100001 & 00111111 = 00100001 |
| add the results | 10000000 + 00100001 = 10100001 = 0xa1 | |
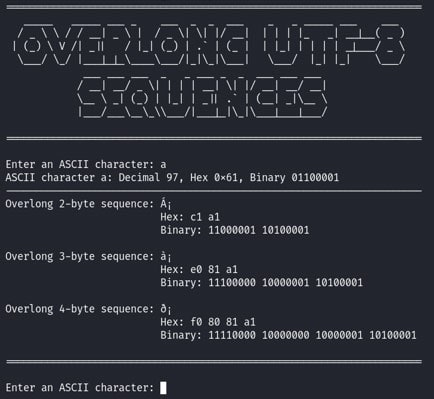
Longer byte sequences are computed analogously. The script then returns the overlong sequences along with their hex and binary representations. The following screenshot shows the script’s output for the input ‘a’:
Summary
While the topic of overlong UTF-8 encodings may seem niche, its implications for cybersecurity can be significant if suitable mitigation measures are not in place. As pentesters, staying vigilant and informed about such vulnerabilities and the right tools and techniques to effectively detect and mitigate their potential risks is crucial. By revisiting older and often-overlooked vulnerabilities, we can better understand not only how such risks arise but also appreciate the importance of adhering to modern security best practices, such as encoding standards. Let us not forget the lessons from the past as we continue to fortify our defenses against the evolving landscape of cybersecurity threats.