
Florian Haag, dual student in computer science at usd HeroLab, developed a tool chain to automatically detect cloned websites related to phishing attacks during his practical semester at the University of Applied Sciences Darmstadt.
Here he gives us an introduction to the topic:
Abstract
The threat that phishing poses to businesses and private persons has been growing constantly over the past few years. While e-mail is the main means of communication fraudsters use to try to trick people into trusting them, they finally are redirected to a website pretending to be from a trustworthy business. The goal of the work presented below is to detect cloned websites related to monitored domains that are pre-configured in the tool chain. This chain has two stages: aggregating potential phishing/clone domains from various sources and, in stage two, automatically verify that the sites are indeed valid clones. Over the past two months, this tool chain successfully identified several cloned websites.
Introduction
The internet is huge, as measured by the number of active websites. While most of them are associated with legitimate businesses and private persons, some websites are used for malicious purposes such as phishing. The sites pretend to offer services they are not going to deliver. Instead, they are stealing personal data or login credentials. The following post describes the development of a tool chain that tries to automatically find and identify sites related to phishing. Therefore, several existing domain sources are connected with newly developed tools that merge into a pipeline outputting domain names of sites that have a high likelihood of being malicious. The following sections outline the challenges of the task at hand, describe both stages of the pipeline and summarize the results.
Challenges
When searching for cloned websites potentially related to phishing, several challenges arise. The biggest problem is the size of the internet, which makes it hard to sift through the huge amount of registered domains. According to The Domain Name Industry Brief published in March 2019, there are approximately 348.7 million domain names registered across all top-level domains (TLD)[1]. This number only contains all domains consisting of one subdomain and a top-level domain (e.g. example.org). To broaden the search space further, every domain can have an arbitrary number of additionally prepended subdomains (e.g. www.example.org, web.example.org).
Another challenge is the short-lived nature of phishing sites. Some only remain active for a short time-period, such as 48 hours, in order to avoid detection. Others are shut down as soon as the fraudsters have reached their target. In order to find those phishing sites, the process of searching has to be quick. In more concrete terms: The data used for the search should not be older than 2-3 days. Also, the faster a clone can be found, the fewer people may have already fallen victim to it.
Up to now, the challenges only relate to the process of aggregating domain names of potentially cloned websites. Another task is to visit those sites and to decide whether a site is a clone or a legitimate website not aimed at tricking its visitors. Because the expected amount of incoming data from the search process will be huge, an automatic approach that filters domains and checks their availability needs to be developed. The domains that are still active need to be rated in order to determine their likeliness of being clones.
The thoughts about the challenges lead to a two-stage layout. The first stage is used for aggregating domain data from several sources. Furthermore, this stage filters the input data for certain patterns in the incoming domains and therefore sifts out domains that are more likely to host a cloned website. The second stage receives the results from stage one as input and tries to compare the websites behind the domains against references of monitored originals. The following sections describe in detail the stages and their respective implementation.
Preconditions
In order to enable the tool to work efficiently, it is not feasible to search for every clone on the web. Therefore, the tool uses a pre-configured set of websites/businesses, as starting point for the search. The names of those websites/businesses are used to filter incoming domain names in stage one and act as a references for the automatic identification in stage two. Adding new businesses to the tool in the future is possible by expanding the list of domain name filters and adding references of the respective sites. Therefore, no code changes are required for adding a new target.
Data aggregation (stage 1)
The first stage’s main task is to accumulate domains/URLs from several sources and filter them for their potential to host a cloned or phishing website. A first source for domain names is the typosquatting technique, which utilizes certain heuristics to generate domain names closely related to a starting domain. Typosquatting exploits misspellings that can happen when visiting an URL. Starting with the domain www.example.org such heuristics are for example:
- Forgetting letters (www.exmple.org)
- Doubling letters (www.exammple.org)
- Switching letters (www.exmaple.org)
- Typing adjacent letters on the keyboard (www.exanple.org)
To generate such domains the tool dnstwist[2] can be used. This tool supports the techniques mentioned above, but also further techniques such as exploiting the differences between character sets used for encoding textual information inside a computer. The domain names generated with the typosquatting approach can be integrated into the tool and regularly checked if a clone is hosted on one or more of those domains.
A second approach for accumulating domain data is to parse the list of newly registered domains. For the .com top-level domain, this list is released daily, for the previous day, and can be downloaded for free. The list for the .com top-level domain alone consists of approximately 100.000 entries per day. While data for the .com domain is easily accessible, most other domain registration authorities keep their data hidden. In order to filter out domains related to the businesses of interest for us, several regular expressions were created that are matched against every entry in the list.
Another source are the Certificate Transparency (CT) logs. These CT logs are an append-only data structure where Certificate Authorities, which are responsible for issuing TLS certificates, add data about their latest changes. In the last years, the usage of TLS in form of HTTPS for securing web traffic has been rising constantly and owners of cloned sites are moving to secure their sites with such certificates. An advantage of this source is that every certificate contains the domain name (sometimes including the sub-domains) of the web server that the certificate was issued for. To parse these logs, a utility called certstream[3] is utilized. This creates a continuous stream of certificates (new or renewed) added to the CT logs. The tool parses the stream and extracts the domain names from every incoming certificate.
In order to filter the incoming data provided by the certstream library, I developed a tool called certfilter. This tool extracts the domain names from the TLS certificates in the stream and filters them using regular expressions. These regular expressions are pre-configured to match the businesses and websites monitored by the tool chain. This leaves us with about 10.000 per day. As this number is still too large for manual review, a rating algorithm calculates a score based on features mostly observed in phishing/cloned domains:
- Inner top-level domain (e.g. www.example.com.testing.org)
- Length > 25 characters
- Certificate issuer is Let’s Encrypt CA
- More than 3 subdomains (e.g. www.web.test.foo.example.com)
- More than 4 dashes in domain (e.g. www.account-sig-in-test.this-example.com)
- Domain contains keywords (e.g. account, signin, login, etc.)
For every feature, a certain amount of points is added to the total score. This score enables the tool chain to further classify the results, because only relying on textual matches with regular expressions leaves too many candidates most of which are not containing cloned websites. The following screenshot shows the certfilter running with four supplied regular expressions. In the brackets in front of the domain name, the score assigned to the corresponding domain is displayed. Regular expressions as well as filtered domains are blurred in order to protect the owners of a legitimate site that was captured by certfilter.
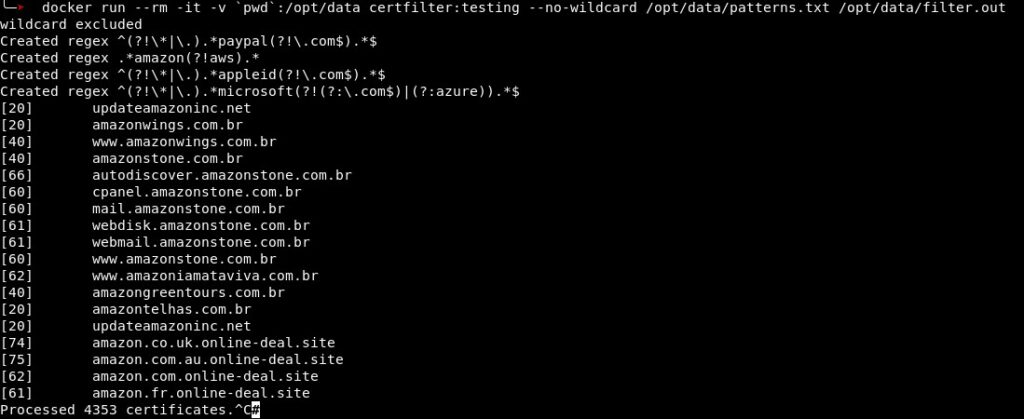
All in all, the three sources evaluated lead to about 500-1000 domains per day that need further processing. The typosquatting approach is the least important because it only needs to be run on a weekly basis, as the resulting domains are always the same and only changes in ownership on those domains would be detected. The daily registered domains are automatically filtered every day and result on average in 100 domains per day. The majority of data is extracted from the CT logs with about 500 matches every day. A potential fourth source could be e-mail, as it is a popular way of spreading links leading to malicious websites. It was not considered as an input for the current pipeline due to the high effort and resources needed for a setup delivering usable results.
Identification (stage 2)
After stage one reduced the input data to domains that belong to our monitored businesses/websites and rated some of them to further enable classification, the goal of stage two is to identify the cloned sites in the remaining data. Up to now, only domain names have been accumulated from registrars or TLS certificates. The first task in the identification stage is now to check the availability of those domains. Registration of a domain or issuance of a certificate does not automatically mean that there is a corresponding website available. Thus, the tool scamsearcher was developed that processes a list of domains in the following steps:
- Optionally filter the input domains with regular expressions.
- Check DNS resolution
- Check web server availability on HTTP (80) and HTTPS (443)
- Take screenshots for available ports (80 and/or 443)
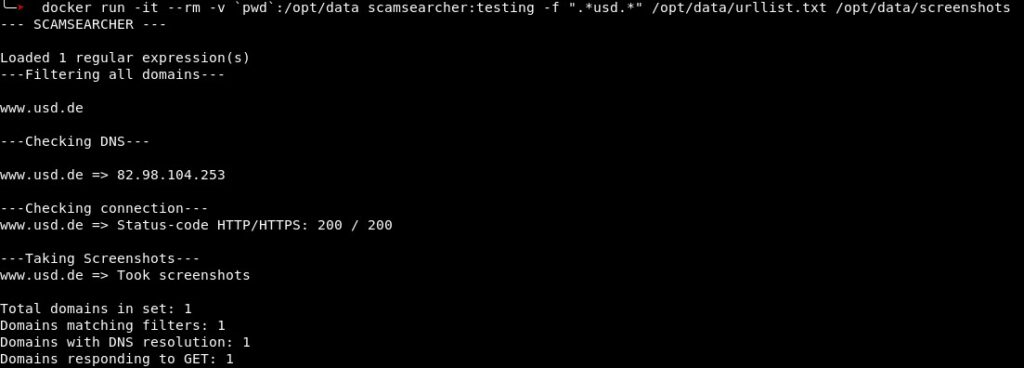
With every step, the number of potential domains decreases. The screenshot below shows scamsearcher in action for an input data set only containing the domain name www.usd.de. The tool leaves us with the domains reachable by HTTP or HTTPS (or both), as well as screenshots of the respective sites. Furthermore, the remaining domain names are added to a queue that serves as input for the identification utility following in the pipeline.
The automatic identification of actual website clones is a non-trivial problem because it has to deliver good performance on all sorts of websites with different technology stacks and target audiences. In the process of developing an identification system, several approaches turned out to be unsuitable as a stand-alone solution to this challenge.
The first is Fuzzy Hashing, where the HTML of the potentially cloned site is split into small junks that are hashed individually. These sub-hashes are then combined into a so-called Fuzzy Hash representing the website. In order to compare two sites, the Fuzzy Hashes of both sites are calculated and these hashes are compared. The similarity between the sub-hashes is equivalent to the similarity of the two websites compared. While evaluating the performance of this approach, it could be observed that some cloned sites are not actually a “clone” but rather a re-implementation of the original. Therefore, the Fuzzy Hashing approach over the HTML-sources had too many false-negatives to be considered a suitable mechanism for identification.
The second approach was an image comparison process of the screenshots taken by the scamsearcher. For comparison, the SIFT (Scale-Invariant Feature Transform) algorithm, popular in the image processing field, was chosen. Briefly explained, this algorithm calculates feature vectors for key-points in the images, which can be compared. One problem with this approach were pop-ups on the website that distort the screenshots and falsify comparison results. The most significant drawback was the run time of the image comparison, as the algorithm is computationally expensive. For the expected throughput of the pipeline, the comparison of images had too many false-negatives and took too long to conduct.
A major problem with both of the already mentioned approaches is that every part of an input website is considered equally important. However, there are certain pieces of information, for example visible texts, that are more important for the decision, whether it is a clone or not. Therefore, the third approach employs a self-implemented rating logic, contained in a tool called scamverifier. As with certfilter, scamverifier calculates a score that rises according to predefined heuristic metrics. The following overview lists the metrics that are contained in the calculation for the similarity score of a candidate and the corresponding reference:
- Website title similarity >= 90%
- Links pointing to reference domain
- Similarity of javascript files >= 90%
- Keywords of reference occurrences in title, headings and texts
- Similarity of texts >= 90%
Metrics 2 to 5 are evaluated for every element in their respective group. Meaning for example, that every script on the target website is compared against the scripts on the reference site. If their similarity is at least 90% the points assigned to this metric are added to the total score. The following screenshot shows scamverifier comparing an example site, which is also the original, with its reference.

scamverifier is the tool that is currently used for identifying websites as clones that result from the previous stage one and the availability check by scamsearcher. The main challenge is to adjust the scores for the individual metrics. Because most of the features for a metric can occur with varying frequency, there is no upper limit for a score. For example, a site that contains a lot of text can achieve a high score when the texts in the candidate and the reference have high similarity. This makes it hard to determine a threshold that distinguishes identified clones from the rest. After some adjustments on the individual scoring of certain metrics, scamverifier could successfully identify cloned websites. From the candidates that were suspected clones, all actual clones could be identified (no false negatives). The problem with the limitless score led to only a few false-positives, where sites that actually had no malicious intentions were considered clones.
Pipeline Overview
Before briefly talking about the overall result of the development efforts made, a short overview of the pipeline is given.
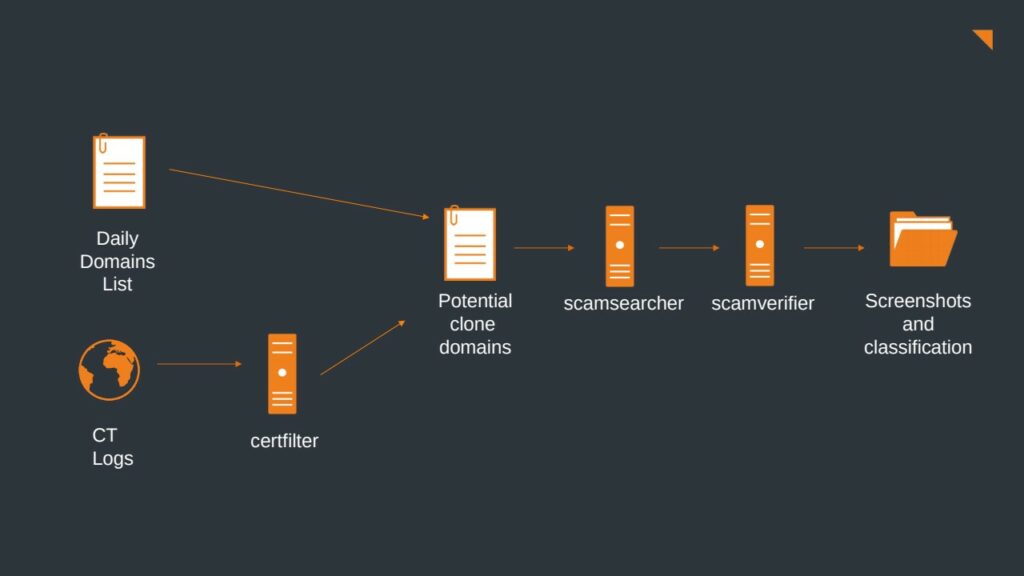
On the left, the data sources, daily registered domains and the CT logs are the base for the pipeline that deliver the input. Typosquatting is not shown in the picture because it is not a constant source of input and therefore not as important as the other two. The data from the CT logs is filtered and rated by certfilter, which only forwards domains with a score above the threshold. All domain data is then accumulated in a central queue of domains that need to be identified. On a regular basis,scamsearcher is triggered to check the availability of every domain and only forward those that are reachable (including screenshots of these sites). Then, scamverifier applies the rating algorithm to every site and calculates a score for every candidate. Finally, all candidates with a rating above the scamverifiers identification threshold are stored, together with the respective screenshots, in an output folder. Here, an operator can finally decide whether it is a valid clone or not and take appropriate actions.
Responsible Disclosure
According to our mission “more security.” as well as our responsible disclosure[4] policy, the verified phishing websites are reported to the website phishtank.com, which appends them to a public list of phishing websites. The community reviews every submitted domain and either verifies or discards false submissions in order to improve the quality of the list. PhishTank offers this data for free via an API that can be utilized by third parties. The data from phishtank.com is monitored by businesses affected from phishing as well as domain registrars, hosting providers and antivirus vendors. Adding the domain of a phishing site to the list of phishtank.com led in most cases to a quick takedown of the clone. Furthermore, antivirus software and browser vendors include the domain in their products protection mechanism, which for example warn users before visiting a malicious site. The main advantage of reporting phishing domains to PhishTank is, that not only the owner of the cloned sites, but also third parties (e.g. hosting providers, browser vendors), can use the information and protect users from such websites.
Example
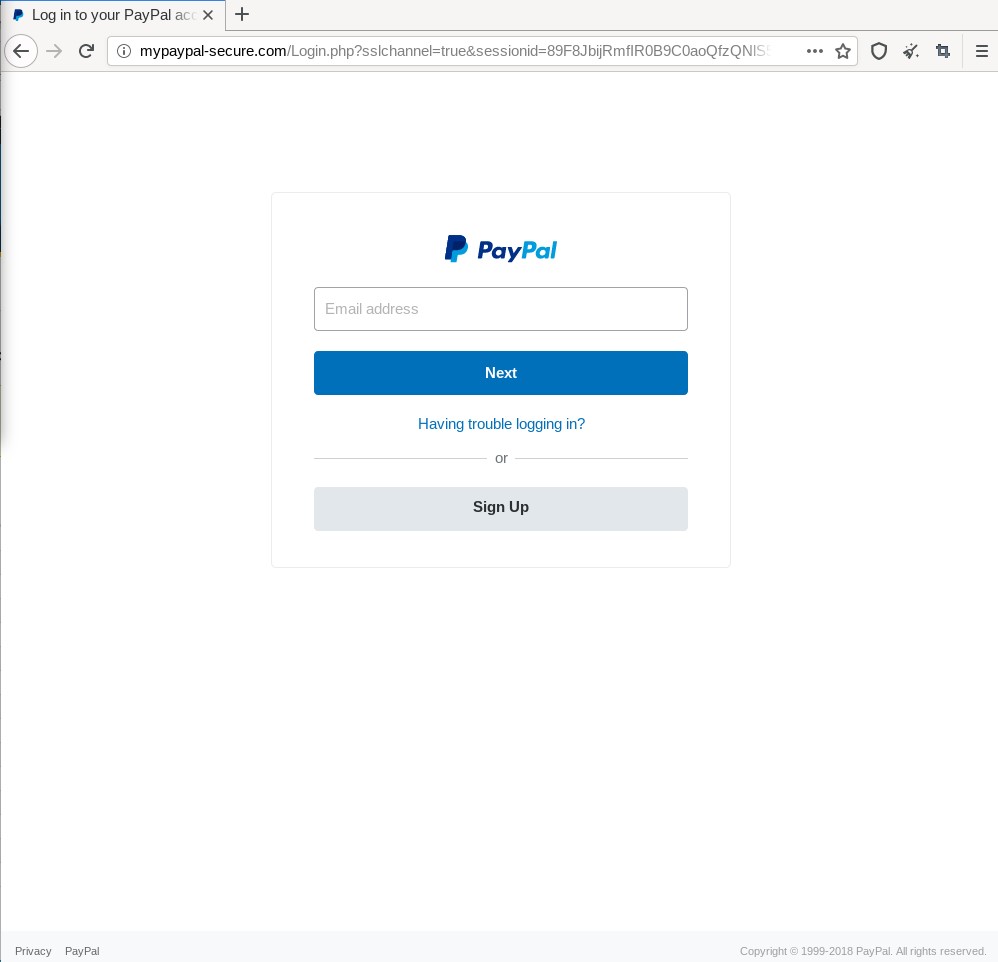
The screenshot below shows a concrete example for a found and verified website clone. Here the fraudsters cloned the PayPal account login form to obtain login credentials for existing accounts. The browsers address-bar shows the domain mypaypal-secure.com. By the time, the tool chain found the website the domain was, according to the associated whois data, not related to the business of PayPal. Furthermore, the website uses the HTTP protocol without SSL/TLS, which means the entered credentials are transmitted to the server in clear text, without encryption. Most login forms as of today employ HTTPS to protect the sensitive data in transit. Another indication is that all buttons and links on this site, except the “Next” button are without function. This also shows that the sites sole purpose is to collect entered credentials. The tool chain could find the site, because its domain name appeared in the list of daily registered domains for the .com TLD. After reporting the site to phishtank.com, it disappeared about 24 hours later. Furthermore, the site was included in Firefox’s list of known phishing sites, so the browser displays a full-size warning message warning users that they are about to visit a phishing site.
Results
To further substantiate the results, some numbers on the pipelines performance are presented. During a time-period of about 2 months, five globally-acting companies (Amazon, Apple, PayPal, Microsoft, Facebook) were monitored and considered as targets for the pipeline. These companies were chosen by their global reputation as this correlates with to the likelihood to fall victim to fraudulent website cloning. For every site, the main account login page was included in the monitoring pipeline. In the mentioned time period, about 100 websites not related to the original businesses were identified as valid clones, all of them related to phishing campaigns. Nearly all of them were taken down quickly after reporting them.
In the spirit of usd’s mission “more security.”, the pipeline remains active and tries to find as many clones as possible. One possible measure is to report identified clones to the respective domain registrars, legitimate owners and vendors of antivirus solutions and browsers. This way, users can be protected from the attempted fraud.
[1] Verisign, The Domain Name Industry Brief, Volume 16 – Issue 1, March 2019
[2] https://github.com/elceef/dnstwist
[3] https://github.com/CaliDog/certstream-python
[4] usd HeroLabs‘s responsible disclosure guidelines (https://herolab.usd.de/responsible-disclosure/)